| RENT A THINKER |
|
|
|||||
| Home | My Page | Chat | Tik-Tok | ||||
2.1
Abstract
2.2
Introduction
2.3
Design Approach
2.4
Character Separation Algorithm
2.5
Character Recognition
2.6
Results
2.7
Reference
Hand written character
recognition is one of the focused area of research in the field of Artificial
intelligence. It involves image digitisation, line separation, character
separation, image enhancement, data compression, segmentation, image recognition
and contextual error correction. This paper describes a neural network based
technique to recognize isolated hand written characters. This method involves
hierarchical feature extraction and classification.
A neural network based
algorithm is developed using Visual C++
to recognize hand written characters. The network is based on Multi Layered Feed
Forward type network with 64 binary inputs and 26 binary outputs. The system
consists of other modules like- page scanner, line separator, character
separator, character normalizer etc. The network software performs off-line
training and character recognition. This design is only for uppercase English
character set.
The weakest link between the
computers and its user is the inputting systems; in most cases is the keyboard.
There are various ways, where
computers directly take input
from the human information system like- optical character recognition
(OCR), speech recognition, symbolic (Icons, windows) interactive communication
etc. Such systems are difficult to design and do not provide complete error free
operation. General solution for speech or character recognition is very complex.
Even fastest computers would need much larger computational time compared to
human response time to perform the
same job. To get working solution for the above class of problems, domain
specific solutions are much more efficient.
In hand written character
recognition problem, the domain is reduced to a small subset of characters of
limited number of written characters using specific style. This subset is then
further classified to smaller subsets, where each group represents a character.
The character space is visualized as space confined by non-linear decision
boundaries separating the characters from each other. Any overlap in decision
boundary causes erroneous recognition. Hence the design goal is to make as crisp
boundary as possible in the domain space so that ambiguity of the character
subset recognition is reduced to minimum.
As described above, the domain
space in case of digitized hand written text could be in vector or raster
graphics format. In case of on-line text entry (using mouse, light pen or
graphics tablet) each individual strokes (vector) is recorded. and in case of
text data on paper, raster scanning method is used for digitization using
optical scanner or video camera. Raster to vector conversion is very complex
process. Hence we choose the raster format,
as standard input for both on-line and off-line texts.
A scanner of 600 dpi gives
approximately 64 x 64 pixel resolution for an average hand written character.
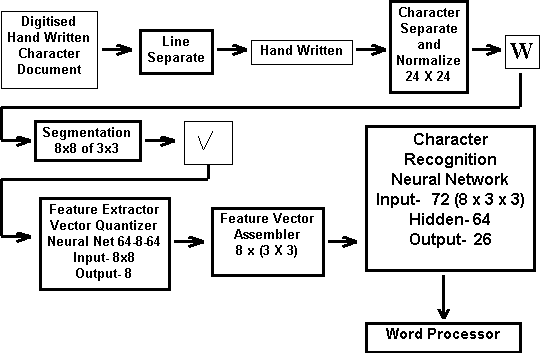
Figure-1 shows the block diagram of the proposed system.
Figure-1. The
block diagram of a Hand Written Character
Recognition System using Neural Network based feature extraction and feature
classification.
The size and shape of a hand
written character may vary considerably in a given text.
It is necessary to normalize both size and shape of a character before
presenting it to an OCR engine. Size
normalization needs contraction and/ or expansion with minimum distortion in
aspect ratio, so that the character fits to a fixed template (e.g. 24x24).
The size-normalized data is
segmented in small zones (e.g. 8x8) to examine the content to codify and
quantify in terms of shape parameters. This is achieved by vector quantization
technique as shown in figure-2. Each segment is represented by a small set of
parameters (shape vector). This process further reduces the data size
approximately to one tenth and normalizes the shapes.
In
the next step all the shape vectors corresponding to a character are assembled
back. The feature vector set is then classified using another multilayered
neural network (72 - 64 - 26). There are 26 outputs of this network each
represents a specific character that may be written in different shapes or
sizes. The model of vector quantization and classification is based on large
data set and needs to be computed off-line using supervised training.
A statistical sampling
technique is used to increase the speed of
the character separation from
hand written script. In this method
random samples are taken from middle of each side of the paper to locate the
limits of the script boundary. Similarly, the line and character boundary are
detected by searching horizontal blank line for line separation and vertical
blank space between consecutive characters. This method is found 10 - 15 times
faster than the continuous raster scan method.
However, being statistical in nature, the method at times misses the gaps
and combines two characters together. An alternative method is used
to scan alternate pixels and scan lines. This method is four times faster
and found error free. Figure-3 is showing character isolation and boundary
detection result. The boundary separation data is stored in a separate file and
is presented to the character normalization module.
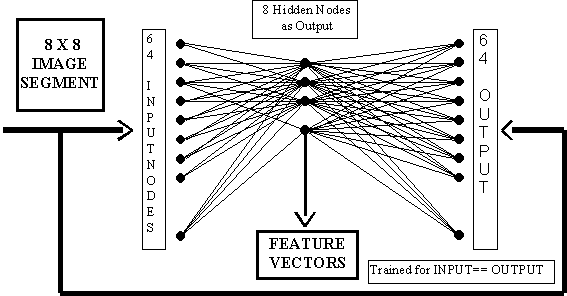
Figure-2. Feature extraction from a hand written
character segment. In above diagram 64 output neurons are trained to reproduce
64 input neurons (8x8 image segment) through 8 hidden neurons. The hidden node
outputs are used to further classify the character.
The character recognition involves
comparing of target character’s attributes with the set of stored templates.
The best match, if found above a pre-defined threshold, is declared as
recognized to corresponding template. For contextual recognition it is necessary
to store a list of top matches. Simple spell check algorithm is used to select
the most appropriate character from the list. The selected character may not be
always at the top of the list. Also
when the character is outside the domain of stored templates, the best match is
found below the acceptable threshold value. It is desirable to choose optimum
set of attributes for the best results. The total score of match is computed by-
M=S
at x as
Where at is
attribute of the template
and as is the attribute
of the sample.
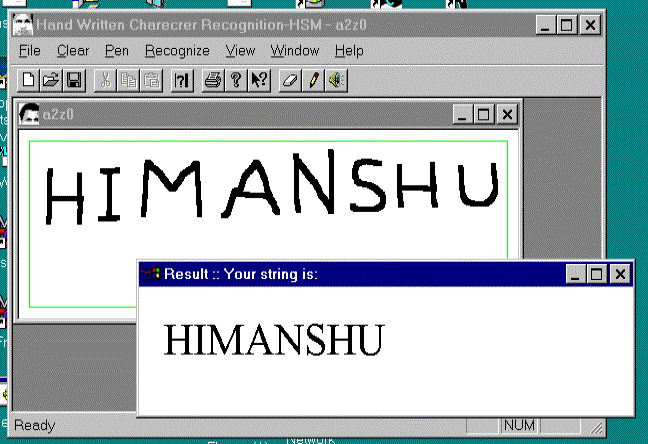
Fig-3 A sample run of Hand Written Character
recognizer package developed by author.
In the hand written characters the
attributes could be visualized as different shape properties associated with a
character like for e.g. curvature, straight line, corner etc. To extract
dominant shape parameters from a large set of characters, the character field is
divided into small segments (8 x 8). Each segment data is presented to a
sand-clock shaped neural network having equal number of input and output nodes
and fewer hidden nodes (see figure 2). When the network reproduces the input at
the output (using back propagation learning algorithm), the hidden neuron
outputs the dominant features. To recognize a sample character, it is divided
into small zones (3 x 3) and the
dominant attribute corresponding to each zone is measured. The classification of
this set is tested with another feed forward type neural network (see figure-1),
which is previously trained with the full set of templates.
A prototype handwritten character recognition package is
developed using Visual C++ to
recognize handwritten upper case English letters. The system uses mouse as input
device. The input text is read from the graphic screen directly. Figure 3 shows
a sample output of the package.
1.
Himanshu S. Mazumdar, Leena Rawal, “A Learning Algorithm
for Self Organized Multilayered Neural Network” CSI Communication, pp.5-6(May
1996)
2.
Leena P. Rawal, Himanshu S. Mazumdar, “A DSP based Low
Precision Algorithm for Neural Network using Dynamic Neuron Activation
Function” CSI Communication, p.15-18 (April 1996)
3.
Leena P. Rawal, Himanshu S. Mazumdar, “A Neural Network
Tool Box using C++” CSI Communication, pp.22-25 (April 1995)
4.
Hetcht-Nielsen, "Theory of the back propagation neural network,
“in Proc. Int. Joint Conf. Neural Networks, vol.1, pp.593-611. New York: IEEE
Press, June 1989.
5.
Lippmann R.P., An introduction to computing with Neural Nets.IEEE ASSP
Magazine, pp4-22, April 1987.
6.
Rumelhart and J.L. McClelland Parallel Distributed Processing:
Explorations in the Microstructure of Cognition. Cambridge MA: MIT Press, vol.
1,1986.
2.8
Published:
Himanshu S. Mazumdar., “Hand Written Character
Recognition using Neural Network " CSI Communication, p.16-18 (Feb. 1998)